


今天的世界充斥着数据——来自我们使用的设备、我们构建的应用程序和我们的交互。各行各业的组织都利用这些数据进行数字化转型并获得竞争优势。现在,随着我们进入由人工智能主导的新时代,这些数据变得更加重要。
生成式人工智能和语言模型服务,如 Azure OpenAI 服务,使客户能够使用和创建日常人工智能体验,从而重塑员工的时间使用方式。为组织特定的人工智能体验提供动力,需要一个管理良好、高度集成的分析系统不断提供干净的数据。但大多数组织的分析系统都是由专业化和互相不关联的服务组成的迷宫。
考虑到大量分散的数据以及拥有数百家供应商和数千项服务的人工智能技术市场,这也就不足为奇了。客户必须将来自多个供应商的一组复杂的互不关联的服务缝合在一起,并承担使这些服务一起运行的成本和负担。

是什么让 Microsoft Fabric 与众不同?
Fabric 是一种端到端分析产品,可满足组织分析需求的各个方面。但有五个领域真正将 Fabric 与市面上的其它产品区分开来:
1) Fabric 是一个完整的分析平台
每一种分析类项目都具有多个子系统。每一个子系统都需要一系列不同的功能,通常需要由多个供应商提供。整合这些产品很可能是一个复杂、脆弱而又昂贵的工作。
使用 Fabric,客户可以使用具有统一体验和架构的单一产品,该产品提供了开发人员通过数据分析提取见解并将其呈现给业务用户所需的所有功能。通过提供软件即服务(SaaS)的体验,一切都会自动整合和优化,用户可以在几秒钟内注册,并在几分钟内获得真正的商业价值。
Fabric 为分析过程中的每个团队提供了所需的特定角色体验,因此数据工程师、数据仓库专业人员、数据科学家、数据分析师和业务用户都感到宾至如归。
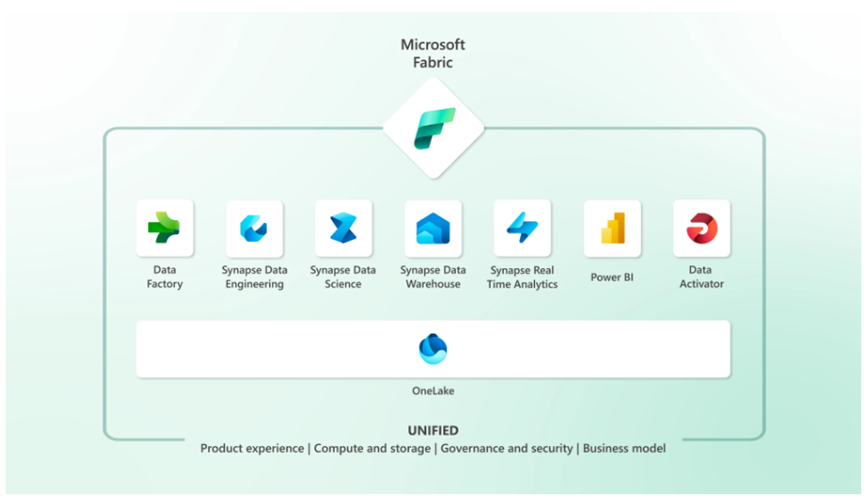
Fabric 有七个核心工作负载:
- 数据工厂(预览)提供了 150 多个可以连接到到云和本地数据源的连接器,用于数据转换的拖放体验,以及编排数据管道的能力。
- Synapse 数据工程(预览)为 Spark 提供了出色的创作体验、即时启动实时池以及协作能力。
- Synapse 数据科学(预览)为数据科学家提供了一个端到端的工作流程,用于构建复杂的人工智能模型,轻松协作,以及培训、部署和管理机器学习模型。
- Synapse 数据仓库(预览)提供了一种统一湖屋(lake house)和数据仓库体验,在开放数据格式上具有业界领先的 SQL 性能。
- Synapse 实时分析(预览)使开发人员能够处理来自物联网(IoT)设备、遥测、日志等的数据流,并以高性能和低延迟分析大量半结构化数据。
- Fabric 中的 Power BI 提供了业界领先的可视化和人工智能驱动的分析,使业务分析师和业务用户能够从数据中分析出并获得见解。Power BI 体验还深度集成到 Microsoft 365 中,在业务用户已经工作的地方提供相关见解。
- 数据激活(即将推出)提供对数据的实时检测和监控,并可以在发现数据中的指定模式时触发通知和操作——所有这些都是无代码体验。
2) Fabric 以数据湖为中心且保持开放
如今的数据湖可能是混乱而复杂的,这使得客户很难创建、集成、管理和操作数据湖。而且一旦投入运行,在同一个数据湖上使用不同专有数据格式的多个数据产品可能会导致严重的数据重复和对供应商锁定的担忧。
一个数据湖(OneLake) — 针对数据的一个数据副本(OneDrive)
Fabric 提供了一个名为 OneLake 的 SaaS、多云数据湖,它是内置的,且自动适用于每个 Fabric 订阅户。所有 Fabric 工作负载都会自动连接到 OneLake,就像所有 Microsoft 365 应用程序都会连接到 OneDrive 一样。数据被组织在一个直观的数据中心里,并自动建立索引以实现发现、共享、治理和法规遵从性。
OneLake 为开发人员、业务分析师和业务用户提供服务,帮助消除由不同开发人员调配和配置自己的独立存储帐户所造成的普遍而混乱的数据孤岛。相反,OneLake 为所有开发人员提供了一个单一、统一的存储系统,通过集中强制执行策略和安全设置,可以轻松发现和共享数据。在 API 层,OneLake 建立在第二代Azure 数据湖存储(Azure Data Lake Storage Gen2)(ADLSg2)的基础上,并与之完全兼容,可立即利用 ADLSg2 庞大的应用程序、工具和开发人员生态系统。
OneLake 的一个关键功能是“快捷方式”。OneLake 允许用户和应用程序之间轻松共享数据,而无需不必要地移动和复制信息。快捷方式允许 OneLake 在 ADLSg2、亚马逊简单存储服务(Amazon S3)和谷歌存储(即将推出)中虚拟化数据湖存储,使开发人员能够通过云进行数据组合和分析。
通过分析产品开放数据格式
Fabric 在其所有工作负载和层中都致力于开放数据格式。Fabric 将 Parquet 文件之上的 Delta 视为所有工作负载的默认本地数据格式。这种对通用开放数据格式的深度承诺意味着客户只需将数据加载到湖中一次,无需分开加载,所有工作负载就都可对同一数据进行操作。这也意味着 OneLake 支持任何格式的结构化数据和非结构化数据,为客户提供了完全的灵活性。
通过采用 OneLake 作为我们的数据存储库,采用 Delta 和 Parquet 作为所有工作负载的通用格式,我们为客户提供了一个在最基本级别上统一的数据堆栈。客户不需要为数据库、数据湖、数据仓库、商业智能或实时分析维护不同的数据副本。相反,OneLake 中的一个数据副本可以直接对所有工作负载进行操作。 通过不同数据引擎管理数据安全性(表、列和行级别)对客户来说可能是一场持久的噩梦。Fabric 将提供一个在 OneLake 中进行管理的通用安全模型,所有引擎在处理查询和作业时都会统一强制执行该模型。这种型号马上就要上市了。(待续)
源文链接:Introducing Microsoft Fabric: The data platform for the era of AI | Azure Blog | Microsoft Azure
")

